
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- fractional seconds
- 운영체제별 차이
- jdbc characterencoding utf8mb4
- mysql not equal null
- https
- jdbc utf8mb4
- 운동해서 광명찾자
- Protecle
- yml
- MSSQL
- +9:00
- mysql8업그레이드
- getDateCellValue
- mysql equal null
- sendFractionalSeconds
- MYSQL
- 오블완
- 버전 문자열 비교
- java jdbc utf8mb4 연결 오류
- getEntityGraph
- RootGraph
- 티스토리챌린지
- createEntityGraph
- spring boot
- AuditingEntityListener
- NamedEntityGraph
- load order
- apatch poi
- 1*1000
- mysql =
- Today
- Total
Hello
[MySQL] 특정 조건일 때 join이 필요한 경우 본문
a컬럼의 값이 1 일 때 b컬럼을 다른 테이블과 조인해야 하는 쿼리가 필요해 구글링하다보니
아래 블로그에서 join - on절에 case 문을 작성해 쿼리를 만드는 방법을 보고 오! 해보자! 라는 생각이 들어 테스트 해보았다.
참고 : https://ggmouse.tistory.com/143
테스트
tb_table1

tb_table2
join-on에 case문 사용하는 쿼리
SELECT a.*, b.name FROM tb_table1 a
LEFT JOIN tb_table2 b
ON a.code_id=
case
when a.code =1 then b.id
END;code 값이 1일 때만 조인하는 것을 확인할 수 있다.
위 쿼리를 실제 적용 하기전에 dba분에게 신기한 쿼리가 있음을 공유하며 성능에 이슈가 없을 지 같이 확인해봤는데
tb_table1의 code, code_id 컬럼에 인덱스를 잡아 두었지만 풀스캔 하는 것을 확인할 수 있었다.
Extra에서 Using join buffer (Block Nested Loop) 방식이 사용된 것을 확인할 수 있었다.
join buffer 방식은 type을 ALL, index, range 중 하나가 사용될 수 있으며, 전체 행이 아닌 조인에 관심 있는 열만 조인 버퍼에 저장됩니다.
Block Nested-Loop Join 알고리즘은 외부 루프에서 읽은 행의 버퍼링을 사용하여 내부 루프의 테이블을 읽어야 하는 횟수를 줄입니다.
알고리즘을 확인해보면 대량의 데이터가 처리될 수록 성능이 안좋기 때문에 조인 범위를 줄이지 못하면 비효율 적이다.
속도 = 선행 테이블 사이즈 * 후행 테이블 접근 횟수
WHERE 추가 테스트
where 조건을 걸어 아래 세 가지 조건을 테스트 해보았다.
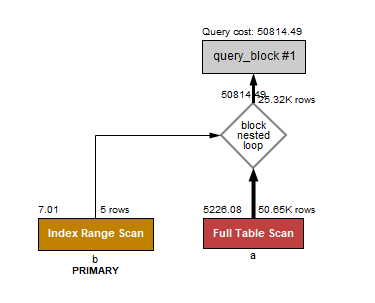
1. WHERE b.id IN (1,5,9,46,81); PK
on절에 사용되는 컬럼 IN 검색 했을 때 type =range 방식으로 조회해 나는 해당 컬럼이 pk 라서 pk index 타는 것을 확인 할 수 있었다.
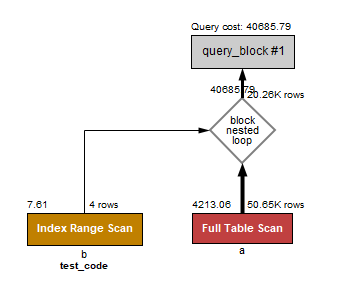
1-1. WHERE b.test_code IN (3,5); KEY
int 타입 컬럼을 인덱스 등록해 테스트 해보니 해당 키로 동작하는 인덱스 타는것을 확인할 수 있었다.

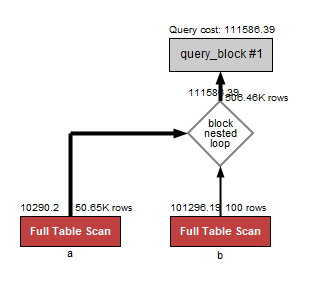
2. WHERE a.desc ='desc73';
인덱스가 잡혀 있지 않는 컬럼 type =ALL 방식으로 조회해 풀 스캔 타는 것을 확인 할 수 있었다.
varchar 타입 컬럼은 인덱스를 잡아도 동일하게 풀 스캔 동작했다. [where b.desc='desc73']

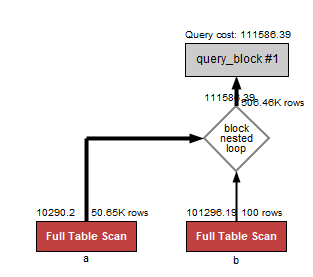
3. WHERE a.code IN (1,3);
2번과 동일하게 풀스캔으로 실행되었음을 알 수 있다.
다른 점은, a.code컬럼은 인덱스가 잡혀있어 possible_keys 에 code 가 들어가 있는 것이다. possible_keys 는 최적의 실행계획을 만들기 위한 후보 인덱스 목록이다.key가 null인 것을 확인 할 수 있는데 code는 최적 계획에 적합하지 않아 사용되지 않았다.

블로그 테스트 및 DBA 의견
dba 분이 위에 블로그의 예시를 테스트 해주셨다. 내가 위에 정리한 내용과 동일 하다.
아래 이미지의 실행계획을 보면 B 테이블의 B,C 컬럼 모두 각각 인덱스 생성된 것을 확인 할 수 있으나, 모두 풀 스캔 성능을 가진 것을 확인할 수 있다.
dba분이 B테이블의 B,C 컬럼에 인덱스를 생성해 두면 어떤 join 조건에도 인덱스를 타지 않을까 생각했으나, 기대와 달리 join-on절은 인덱스 탈 생각 하지 않는 것 같다고 하셨다.
where에 B테이블의 B,C 컬럼 조건을 추가하면 면 인덱스를 타지 않을까? 하는 의문을 제기 하시며테스트 끝..냈다.
where 질의 테스트는 위에 작성해 두었는데 dba분 예상대로 인덱스 타는 것을 확인할 수 있다.
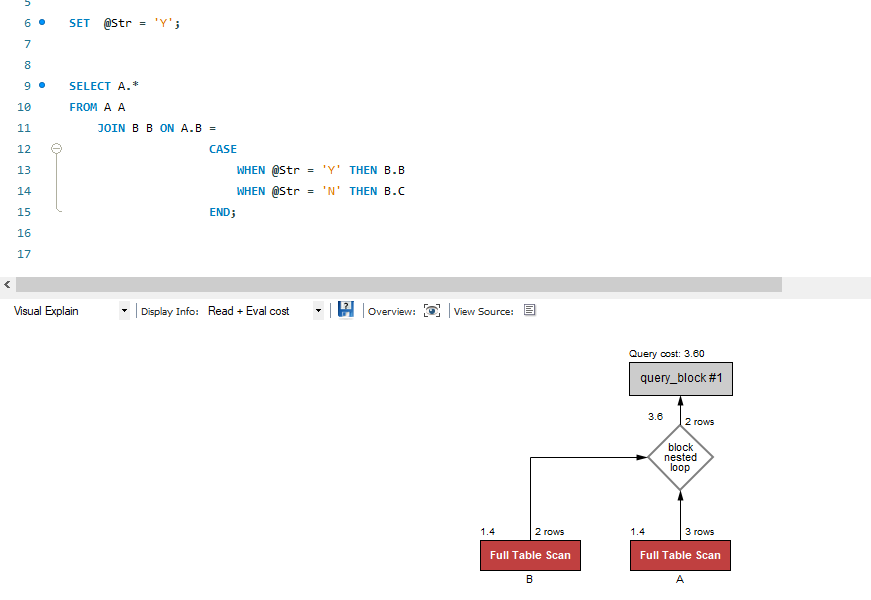
마무리
dba 분이 권장 하는 방법은 2가지가 있었다. 위와 같은 join-on에 조건을 거는 것은 처음 보시는 듯 하셨는데 절대 사용하게 못하게 할거란 말도 덧붙이셨다. 물어보길 잘했다ㅎ...
1. code=1 일때의 쿼리 아닐때의 쿼리 두벌을 작성해 프로시저 또는 백엔드에서 각각의 쿼리를 사용 하는 방법.
2. 쿼리는 join을 걸어서 사용하고 백엔드 에서 code=1일 때만 tb_table.name 값을 사용 하는 방법
참고 : https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html#block-nested-loop-join-algorithm
https://dev.mysql.com/doc/refman/8.0/en/bnl-bka-optimization.html
'DB' 카테고리의 다른 글
| MySql 버전에 따른 JDBC 설정 (0) | 2023.09.01 |
|---|---|
| MySql datetime 반올림 (0) | 2023.08.30 |
| 조회 쿼리 sort 성능 개선 (0) | 2023.07.21 |
| MySQL delete 실행 시 Table disk size가 줄어들지 않음 (0) | 2023.05.18 |
| MySQL FK on update, on delete (0) | 2023.05.17 |


